Do you know why is Kubernetes is the talk of the hour? We need to look at the advent of containers and microservices, which brought us excellent software development and infrastructure capabilities. K8s performs automation with ease, and the Kubernetes Operator aids them a lot.
Kubernetes’s idea was to automate stuff, but then if we need Operators, what’s the whole point of K8s? This blog helps you decode the need and importance of Operators. These are the following topics that I will be addressing in this post:
Before we hop on to Operators, let’s first understand what a Control Loop is.
Control Loop
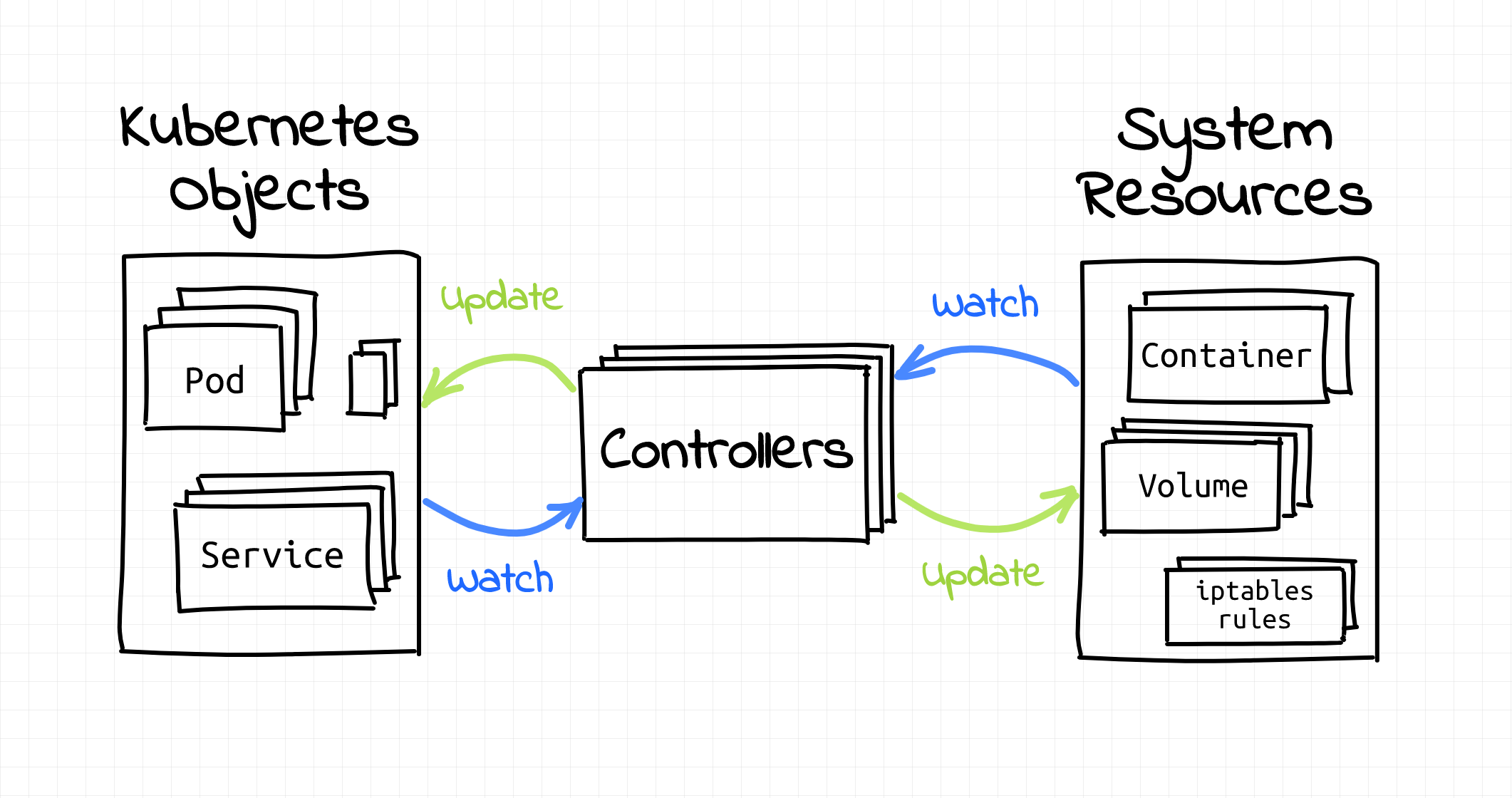
Controllers are no exception in the field of Kubernetes. Since it is all about automation, there has to be an inevitable controller listening to which the K8s runs accordingly. Hence, the controllers reduce the sysadmin toil.

In short, controllers are the control loops that observe the state of a K8s cluster. As a result, make or request changes where required. Every controller strives to move the current cluster state nearer to the desired state.
Controller Pattern

The concept of the desired state comes from tracking a Kubernetes resource type. The desired state of an object is present in the spec field. So, the controller/s responsible for bringing the cluster from the observed state to the desired state. A controller may decide to perform this action independently. But usually, the controller in K8s will communicate with the API server to take the necessary measures.
What is a Kubernetes Operator?
The best practice says that automation is not interfered with by Humans as they are prone to errors. Also, if it comes to us to fix a broken pod in a cluster, scale up and down applications, it defeats the whole point of container automation. For ‘package, it since and run it everywhere‘ to be accurate, there are many other things to address.

An operator in Kubernetes is an application-specific controller. Kubernetes Operators are application-specific and are software written to encapsulate all the operational considerations of an application. It extends a Kubernetes API to create, configure, and manage complicated applications in place of humans. Let us look at an example where an operator deploys a database, upgrades database versions, or performs backups. Therefore, these systems can then be tested and be relied on to react quicker than a human engineer could.
TL;DR – A Kubernetes operator is a method of packaging, deploying, and managing a K8s application. It is application-specific and extends the functionality of the Kubernetes API on behalf of a Kubernetes user.
Also Read: Our blog post on Kubernetes Prometheus. Click here
How does a Kubernetes Operator work?
The operator is nothing but software that does everything a human operator does. So all the tasks of a DevOps member/team are packed into the software. Some of the instructions of deploying an application, creating a cluster of replicas, recovery instructions, etc. It always keeps a watch and gets the application to the desired state.

At its core, the Kubernetes operator has the exact control loop mechanism. It handles the recovering of an application or restarting an application because of the update in deployment. So, Kubernetes Operators are responsible for all the actions performed after changes in the environment.
Everything in Kubernetes runs as containers; Operators are no exception. Below is an example of an Ambassador pattern multi-container and an operator. An operator consists of a code that performs the commands. It also has a Custom Resource Definition (CRD), which maps the operator code back to the kubectl command.
- The operator container contains the program that sees the API and identifies the changes.
- The Ambassador container runs kubectl proxy. It helps in connecting the operator container with the K8s API server.
Also Read: Our blog post on Kubernetes Deployment Strategy. Click here
Why use Kubernetes Operator?
Let’s look at some reasons why the Kubernetes operators are needed:
- The Operators extend Kubernetes functionality.
- Our ideas and knowledge can be defined in an operator.
- K8s Operators do this in a scalable, repeatable, standardised fashion.
- Operators improve resiliency while reducing the burden on IT teams.
- Operators prove particularly useful in multi-cloud and hybrid cloud environments.
Check Out: How to Install Kubernetes Dashboard. Click here
When to use a Kubernetes Operator?
FYI, ‘All operators are controllers, but not all controllers are operators‘. We can choose an existing Operator; on the other hand, you can write it too. But writing operator code will also constrain you from maintaining it. Also, it means that you need more developers to keep the environment robust and secure.
It would be best if you used an operator under the following conditions:
- When you need to encapsulate a stateful application business logic controlling everything with Kubernetes API.
- When you need to build a tool that watches your applications for changes and performs specific SRE/Ops tasks at required times.
Now let’s look at some real-time scenarios where we use Kubernetes Operators that will come into deployment.
Stateless Application on Kubernetes

The first example use case is a web application. You write your deployment, configmap. And service files as per the requirement, and spin up the applications. You also scale the application to the preferred number. In our case, we are scaling it to 3 replicas.
Let’s say one of your application dies for various reasons. So, this is where the Kubernetes comes in and recovers it using the control loop mechanism we saw earlier. Hence a new application gets created and replaces the crashed application. If you make any changes in the deployment configuration, all replicas restart with the latest version.

Wait wait! Should we not take backups? Well, the answer is no, as the application is Stateless. So, here is a perfect example of Deploy once; run it many times. Hence, when you update the deployment or Scale-Up/Down the application, it works pretty much the same without any problems.
Therefore, you don’t need to sit and control the application once deployed, nor need a controller! Kubernetes handles all of these tasks because it is a part of the control loop mechanism. It observes the current state and knows the desired state by the deployment file; it updates the configuration to the desired state.
Also Read: Our blog post on Kubernetes LivenessProbe. Click here
Stateful Application without Kubernetes Operator
Now, we have a web application that requires a database of data persistence. The database applications always possess some state, and we must keep a watch throughout the lifecycle. These applications are called the Stateful applications.

So, if you decide to create three replicas of a database application, their states and identities will differ. Hence, it is a challenge for Kubernetes to handle everything because all the replicas should communicate with each other and be in sync. Also, different databases have different workarounds, so we can’t have a generalised solution for this.
If it is the case that we always need manual intervention doesn’t matter if they run on K8s or traditional servers. So, we require people who “operate” these applications.
But the manual intervention of K8s voids the idea of Kubernetes! The concepts of automation, load-balancing, self-healing capabilities, etc. Don’t jump the gun so quickly; the next section is all the reason you have come here!
Also Read: Our previous blog post on Kubernetes Configmap. Click here
Stateful Application with Kubernetes Operator

So the time has finally come to see an Operator in action. We shall see how the operator enhances the same web application. Using an application-specific operator makes the job easier and effortless after deployment. We don’t need a manual intervention unless there is a significant change in the whole system. Operators are reusable and have a single automated process for all the available similar Kubernetes cluster.

The more challenging the application deployment gets, the harder it becomes for a human operator. Hence, a human operator vs a Kubernetes operator is a no brainer! 🤯
So if an application dies, the operator recovers it without any downtime as it always keeps a watch of the current state. Also, any change in the deployment, the Kubernetes Operator is responsible for restarting the latest versions. The tasks of scale up and scale down are more manageable too!
Conclusion
Kubernetes doesn’t need a business logic for a stateless application; hence, there is no need for an operator. But K8s can’t automate the process natively for stateful applications and thus need the Operators. These operators always keep a watch on the current state and push the application into the desired state. So, you can think of it as a custom control loop as it is application-specific. It makes use of the custom resource definition (CRD) that extend the K8s API. Experts create these operators in the business logic of installing, running and updating that specific application.