Amazon S3 is known to be a promising, stable and highly scalable online storage solution. This what is Amazon S3 tutorial will help you get a basic understanding of Amazon S3 from scratch. You’ll also learn how to create an AWS S3 bucket.
What Is Amazon S3?
Amazon Simple Storage Service (S3) is a storage that can be maintained and accessed over the Internet. Amazon S3 provides the web service which can be used to store and retrieve unlimited amount of data. The same can be done programmatically using Amazon-provided APIs.

Also, S3 in Amazon is provided for free in the free-tier category for 12 months.

What Is an Amazon S3 Bucket?
S3 in Amazon has two primary entities called buckets and objects. Objects are stored inside buckets. Also, it does have a flat hierarchy, not like the one you would find in a file system. But in an organization, a file system is needed in an ordered fashion, and that’s why AWS S3 introduced a file system which seems like a traditional one.
Basically, it works like, if you upload images and you want to differentiate it from other files, you can create a file for it and store it so that the logical address of the file would have the prefix ‘pictures.’ For example, pictures/hello.jpg.
By default, the maximum number of buckets that can be created per account is 100. For additional buckets, one can submit a request for a service limit increase.

Bucket names have to be globally unique irrespective of which region they are created in. As buckets can be accessed using URLs, it is recommended that bucket names follow DNS naming conventions: all letters should be in lowercase.
We’ll also learn how to create an AWS S3 bucket from scratch in this Amazon S3 tutorial, but first, we need to know to have some basic understanding of Amazon S3 concepts.
Amazon S3 Concepts
Now that you know what is Amazon S3 and what is Amazon S3 bucket, let’s move on and discuss some basic Amazon S3 concepts starting from Data Consistency Models.
Data Consistency Models
S3 in Amazon provides amazing highly available and durable storage solutions by replicating the data under one bucket in multiple data centers in the region. Also, the data uploaded to an Amazon S3 bucket never leaves it until you delete it.
S3 has 2 types in the consistency models:
- Read-after-write consistency
- Eventual consistency
Read-after-write consistency for PUTS of new objects in your S3 bucket in all the regions with one limitation. The limitation is that if you perform a GET or HEAD for object which does not exist then first eventual consistency will be provided.
Eventual consistency is provided by AWS S3 when there is PUT and DELETES in all regions.
Storage Classes
Storage classes are used to distinguish between the use cases of a particular object stored in a bucket. There are various types of storage classes and they are listed below.
| Storage Class | Description |
| Standard | Frequently used objects |
| Standard-IA | Infrequently used objects |
| Intelligent-tiering | Designed to optimize storage costs by choosing Standard and Standard-IA for objects |
| One Zone-IA | Infrequently used objects and non-mission-critical data |
| Glacier | Long-term data archiving with retrieval times ranging from minutes to hours |
| Deep Archive | Archiving and rarely accessing with retrieval times averaging 12 hours |
Object Lifecycle Management
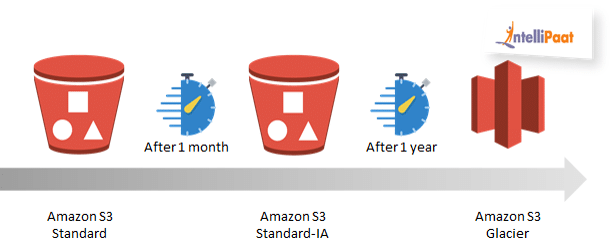
Configuring your object’s lifecycle could ensure they are stored cost effectively for their entire lifecycle. A lifecycle configuration is a set of rules that define actions that AWS S3 applies to a group of objects. There are two types of actions:
- Transaction Actions
- This action defines objects’ transition from one storage class to another.
- You might have provided your object a Standard class at first, then after 2 months you want to make it Standard-IA, and after a year you want to keep it in Glacier.
- Expiration Actions
- This action deletes objects in the Amazon S3 bucket.
- Also, S3 deletes the expired objects on your behalf.
But you might think, why do you need a lifecycle for the objects? Check out these examples.
- You wanted to store log data for the month of April for services; you might need it for a week or a month, and then you might want to delete it.
- You have objects which are frequently used for a week and then they become infrequent. After that, once the usage for it has reduced to the rock bottom, you can archive it and then delete it.
- You also might store data for long-term archiving
Object Versioning
Object versioning provides the flexibility of storing objects with the same name by giving objects version numbers. This prevents unintended overwriting or deletion of the objects.
For example, you have a file called image.jpg with the versioning of 111, and now you are uploading another file named image.jpg, again. So, the newly uploaded image.jpg file will have a versioning of 222. So, they are image.jpg (version 111) and image.jpg (version 222).
Versioning can also be used so that you can compare the older versions of the file.
Encryption
Using S3 default encryption you can set the default encrypted behavior for an Amazon S3 bucket. You can also create a default encryption where every object gets encrypted when stored in a bucket. The objects are encrypted using server-side encryption with either Amazon S3-managed keys (SSE-S3) or AWS KMS-managed keys (SSE-KMS).
Advantages of AWS S3 Service

- Scalability on Demand
- If you want your application’s scalability varying according to the change in traffic, then AWS S3 is a very good option.
- Scaling up or down is just mouse-clicks away when you use other attractive features of AWS.
- Content Storage and Distribution
- S3 in Amazon could be used as the foundation for a Content Delivery Network. Because Amazon S3 is developed for content storage and distribution.
- Big Data and Analytics on Amazon S3
- Amazon QuickSight UI can be connected with Amazon S3, and then large amounts of data can be analyzed with it.
- Backup and Archive
- Whether you need timely backups of your website, or store static files for once, or store versions of files you are currently working on. S3 in Amazon has got you covered.
- Disaster Recovery
- Storing data in multiple availability zones in a region gives the user the flexibility to recover files, which are lost, as soon as possible. Also, the cross-region replication technology can be used to store in any number of Amazon’s worldwide data centers.
Enough with the theory. Now, moving on with this Amazon S3 tutorial, let us see how to create a S3 bucket in Amazon Web Services
Hands-on: Creating an AWS S3 Bucket
Step 1: Login to the AWS Management Console
Step 2: Select S3 from the Services section

Step 3: Click on the Create bucket button to start with creating an AWS S3 bucket

Step 4: Now, provide a unique Bucket name and select the Region in which the bucket should exist. After providing the details click on Next

Step 5: Next is Configure options, and there is no need to provide any details here. You can just click on Next
- But if you want to track costs for this bucket, provide a tag to identify it
- Also, you can choose Versioning. Check the Versioning section of this blog to learn what versioning provides

Step 6: In permissions, keep all checkboxes ticked. This makes the objects in your bucket inaccessible for the public

Step 7: Review once and click on Create bucket


You have successfully created an S3 bucket using Amazon Web Services! This brings us to the end of this Amazon S3 Tutorial.
Hope you found this Amazon S3 tutorial helpful.